Database Normalization
데이터베이스 정규화(Normalization)에 대해 정리하였습니다.
< Introduction to Normalization >
Database normalization is a process by which database tables are modified/restructured to minimize redundancy
< Duplicated Data >
When columns of a database table do not depend on (i.e., describe) the primary key, the same data may be duplicated in multiple places.
Example : Let’s now examine the college table

The primary key of this table is student_id (a unique student identifier), and most of the columns describe characteristics of students, including their:
- name
- class year
- major(s)
- advisor
But, This table also contains columns that do not describe students directly.
the columns advisor_name, advisor_department, advisor_building, and advisor_email describe further details about advisors
meanwhile, major_1_credits_reqd and major_2_credits_reqd describe further detail about majors.
SELECT advisor_name, advisor_department, advisor_email
FROM college
WHERE advisor_name = 'Brunson';
< Problem : Duplicated Data Problem>
Problem1: if we want to modify the duplicated information, we’ll have to make the same updates in multiple locations.
Problem2: new data cannot be inserted into the table until a primary key is known.
Problem1 Example : A faculty member named Professor 'Hill' changes their email address to 'hill@college.edu'
UPDATE college
SET advisor_email = 'hill@college.edu'
WHERE advisor_name = 'Hill';Unfortunately, this could cause problems if there are multiple professors with the same name.
After we run the code above :
| advisor_name | advisor_department | advisor_email |
| Hill | Biology | hill@college.edu |
| Hill | English | hill@college.edu |
| ... | ... | ... |
If advisor information were housed in a separate table, we could have imposed a UNIQUE or PRIMARY KEY constraint on the advisor_email column to make sure that no two advisors have the same emails recorded in our database.
Problem2 Example :
Suppose that the school hires a new advisor in the Computer Science department. The advisor’s name is Professor Algorithm and his email is algorithm1000@college.edu.
Unfortunately, we cannot add a new row to this database table because Professor Algorithm has not been assigned to advise any students yet — and we need a primary key (associated with an individual student) in order to insert a new row of data.
< Problem : Search and Sort Efficiency >
Consider the college table.
Besides the fact that the major-related columns are not directly dependent on the primary key, you may also notice that there are two sets of columns where a student’s major (and related information) can be recorded.
Example :
suppose that your boss is interested in figuring out which majors are most popular. They ask you to produce a table of unique majors along with the number of students who have declared each one, sorted by popularity.
SELECT major_1, count(*)
FROM majors
GROUP BY major_1
ORDER BY count DESC;| major_1 | count |
| History | 53 |
| Political Science | 49 |
| Computer Science | 49 |
| English | 49 |
| Spanish | 47 |
| Geology | 46 |
The problem is that these counts are incorrect — they completely ignore majors recorded in the major_2 column!
To remedy this, we’ll have to join the major_1 and major_2 columns together somehow, creating additional complexity.
< Restructuring the Advisor Columns >
We saw that every student with the same advisor has identical information recorded in all advisor-related columns in the college table.
One way to address this is by moving the four advisor-related columns into their own table, with only one row per unique advisor. This helps ensure every table has its own purpose or concern.
- To create a new table from an existing one, we can precede any query with :
CREATE TABLE new_table_name AS
Example)
CREATE TABLE advisors AS
SELECT DISTINCT advisor_email, advisor_name, advisor_department
FROM college;
ALTER TABLE college
DROP COLUMN advisor_name,
DROP COLUMN advisor_department;
SELECT *
FROM advisors;
< Restructuring the Major Columns >
We need two additional tables (as opposed to one) because the relationship between students and majors is many-to-many (multiple students can have the same major and each student can have multiple majors), while each major has only one value of credits_reqd.
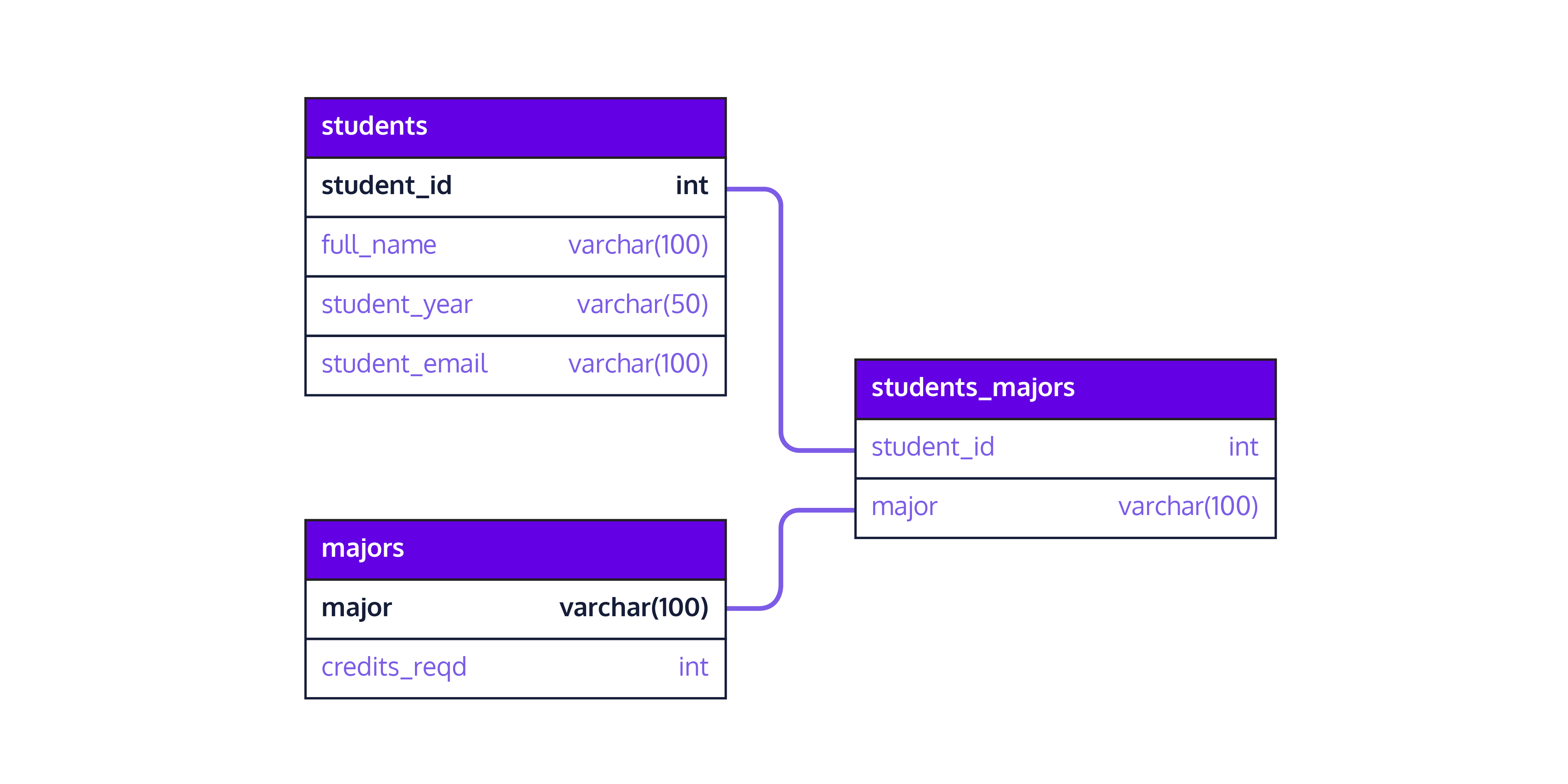
CREATE TABLE majors AS
SELECT DISTINCT major_1 AS major, major_1_credits_reqd AS major_credits_reqd
FROM college
UNION
SELECT DISTINCT major_2 AS major, major_2_credits_reqd AS major_credits_reqd
FROM college
WHERE major_2 IS NOT NULL;
CREATE TABLE students_majors AS
SELECT major_1 as major, student_id
FROM college
UNION ALL
SELECT major_2 as major, student_id
FROM college
WHERE major_2 IS NOT NULL;
ALTER TABLE college
DROP COLUMN major_1,
DROP COLUMN major_1_credits_reqd,
DROP COLUMN major_2,
DROP COLUMN major_2_credits_reqd;
SELECT *
FROM majors
LIMIT 5;
SELECT *
FROM students_majors
ORDER BY student_id
LIMIT 5;
< Creating Versus Modifying a Database Schema >
Moving and dropping columns is also not quite enough to turn the single table from into the many-table version we likely would have designed.
Example :
non-normalized version VS normalized version:

there are some important differences. For example:
- The advisor_name column is renamed name in the advisors table.
- The college table is renamed students because all non-student-related data has now been moved to other tables.
- The primary keys in the advisors, students, and majors tables are now unique integer values. While it is valid to use advisor_email as a primary key in the advisors table, it can make things more difficult when we want to update or delete an email address.
In the four-table schema, we’ll also want to implement some constraints that were either not necessary or not possible in the original version. For example:
- We can now implement a UNIQUE constraint on the email column of the advisors table, ensuring that no two advisors have the same email listed.
- We can also enforce a foreign key constraint on the advisor_id column of the students table so that each advisor_id in that table matches an id in the advisors table.
< Database Structure and Use >
It’s worth noting that normalization does not exclusively make queries and modification easier. When we split a large database table into multiple smaller tables, some queries may actually become more complex.
So, the most important design consideration is how a database will be used in the future.
Example :
If we want to know how many students are advised by faculty in each department, we’ll have to join the students and advisors tables back together.
SELECT COUNT(students.id), advisors.department as advisor_department
FROM students, advisors
WHERE students.advisor_id = advisors.id
GROUP BY advisor_department;| count | advisor_department |
| 68 | Computer Science |
| 53 | Environmental Science |
| 24 | Chemistry |
: That wasn’t too complicated - but note that we could have accomplished the same thing by querying the original college table without any joins!
Article : Database Normalization Basics
The Basics of Normalizing a Database
Database normalization can save storage space and ensure the consistency of your data. Here are the basics in an introductory article.
www.lifewire.com