Designing Database : Database Schema
데이터베이스를 만들기 전에, 어떻게 개요를 잡을지에 대한 방법을 정리하였습니다.
< Introduction >
Like an architectural blueprint, a database schema is documentation that helps its audience such as a database designer, administrator and other users interact with a database.
It gives an overview of the purpose of the database along with the data that makes up the database, how the data is organized into tables, how the tables are internally structured and how they relate to one another.
< When designing a database schema consider the following steps: >
- Define the purpose of your database
- Find the information that make up the database
- Organize your information into tables
- Structure your tables into columns of information
- Avoid redundant data that leads to inaccuracy and waste in space
- Identify the relationships between your tables and implement them
- You can design database schemas by hand or by software. Here are a few examples of free online database design tools:
1. DbDiagram.io - a free, simple tool to draw ER diagrams by just writing code, designed for developers and data analysts.
2. SQLDBM - SQL Database Modeler
3. DB Designer - online database schema design and modeling tool
Example : sample database schema diagram generated from DbDiagram.io

the symbols 1 and * on the lines denote a one-to-many relationship between these tables:
- book and chapter
- book and book_list
- chapter and book_list
< Identifying Your Tables >
First, Define the purpose of your database.
Example :
The purpose of our database is to enable an online bookstore to show its catalog of books to potential buyers and for a buyer to preview sample chapters for a selected book. Imagine you are book browsing on Amazon.com.
Second, Find the information that make up the database.
Example :
After gathering information for this database, we found that our database should have:
- book information which includes title, isbn, number of pages, price, description, and publisher for an overview of the book
- author information which includes author bio and contact
- book chapter information which includes chapter number, chapter title and chapter content that is available for online previewing
=> As you can see, there is quite a lot of information to maintain in our database.
Third, Organize your information into tables.
Example :
a sample row if we decide to store all our information in a single table.
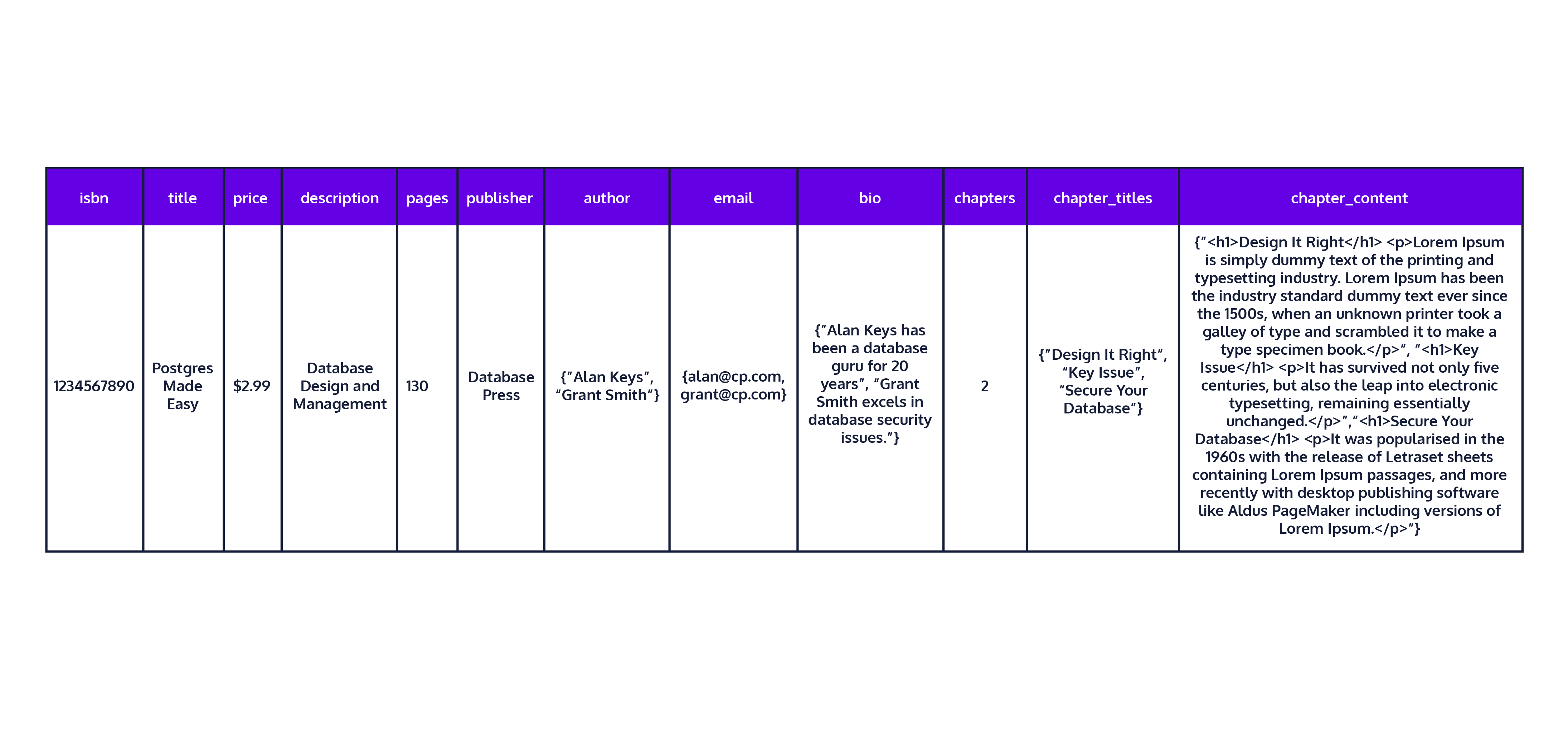
: For the sake of space, we made the chapter information very small and unrealistic.
=> The chapter content is useful when a potential buyer wants to preview a book. But not all books make their content available to the public. In such a case, the chapter content columns will be empty.
To make this table easier to use, storing the chapter content in its own table makes more logical sense. This would also make the current table more lightweight and manageable.
Therefore, we should restructure this table so that chapter-related information resides in its own table.
< Creating Your Tables >
Fourth, Structure your tables into columns of information
Once we have identified our tables for our schema, the next step is to declare what should be in our tables.
Example)
CREATE TABLE book (
title varchar(100),
isbn varchar(50),
pages integer,
price money,
description varchar(256),
publisher varchar(100)
);
CREATE TABLE chapter (
id integer,
number integer,
title varchar(50),
content varchar(1024)
);
CREATE TABLE author (
name varchar(50),
bio varchar(100),
email varchar(20)
);In this example, created book, chapter, author tables.
< Avoid Inaccurate Data >
Fifth, Avoid redundant data that leads to inaccuracy and waste in space
In order to have a useful schema, we need to prevent a database table from storing inaccurate data and returning multiple rows when we expect only one. We do this by constraining the table with the help of a primary key assigned to one or more columns. This will ensure that the column or combination of columns contains only unique values. We will explore this topic further in a next writing on keys.
< Relationships Between Tables >
Lastly, Identify the relationships between your tables and implement them
We will discuss these interesting relationships between tables and how to implement them in next writing about keys and relationships.
Example 1)
Let’s say we have a person table and an email table, where a person can have many email addresses, but an email address can only belong to one person. To implement this type of relationship, we need to apply a constraint on the email table by adding another column to it and designating it to associate with the person table.
Example 2)
Let’s say we have a hobby table as well and populate it with all kinds of hobbies. If we try to query both the hobby and person tables, how do we know for sure that a hobby is tied to a particular person? There is nothing in the person table that links it to a hobby.
To associate a hobby with a person, we need to relate the person table to the hobby table with the type of relationship they have. Can a person have only one hobby or multiple hobbies? Can a hobby apply to only one person or can it be shared by multiple people?